There are generally two ways to dynamically add columns to a dataframe in Spark. A foldLeft or a map (passing a RowEncoder). The foldLeft way is quite popular (and elegant) but recently I came across an issue regarding its performance when the number of columns to add is not trivial. I think it’s worth to share the lesson learned: a map solution offers substantial better performance when the number of columns to be added tends to increase.
Let’s start with an example dataframe with four columns: “id”, “author”, “title”, “incipit” (the opening line of the novel). A simple dataframe with just one row might look something like:
+---+-----------+-------------+-----------------------------+
| id| author| title| incipit|
+---+-----------+-------------+-----------------------------+
| 6|Leo Tolstoy|Anna Karenina|Happy families are all alike |
+---+-----------+-------------+-----------------------------+
You are given an arbitrary list of words and, for each of them, you would like to add a column (named after the word) to the original dataframe and flag with a boolean whether or not that word appear at least once in the opening line (incipit).
For a list of two words List("families", "giraffe"), the above dataframe will be transformed into the following:
+---+-----------+-------------+-----------------------------+--------+-------+
| id| author| title| incipit|families|giraffe|
+---+-----------+-------------+-----------------------------+--------+-------+
| 6|Leo Tolstoy|Anna Karenina|Happy families are all alike | true| false|
+---+-----------+-------------+-----------------------------+--------+-------+
As the list of columns is arbitrary, there are two possible approaches to this problem. I wrapper both in a method to make testing easier. First approach would be the foldLeft way:
def addColumnsViaFold(df: DataFrame, columns: List[String]): DataFrame = {
import df.sparkSession.implicits._
columns.foldLeft(df)((acc, col) => {
acc.withColumn(col, acc("incipit").as[String].contains(col))
})
}
And the second one (which involves a bit more coding) is the map way:
def addColumnsViaMap(df: DataFrame, words: List[String]): DataFrame = {
val encoder = RowEncoder.apply(getSchema(df, words))
df.map(mappingRows(df.schema)(words))(encoder)
}
private val mappingRows: StructType => List[String] => Row => Row =
(schema) => (words) => (row) => {
val addedCols: List[Boolean] = words.map {
word => row.getString(schema.fieldIndex("incipit")).contains(word)
}
Row.merge(row, Row.fromSeq(addedCols))
}
private def getSchema(df: DataFrame, words: List[String]): StructType = {
var schema: StructType = df.schema
words.foreach(word => schema = schema.add(word, DataTypes.BooleanType, false))
schema
}
The code (including all tests) is available here
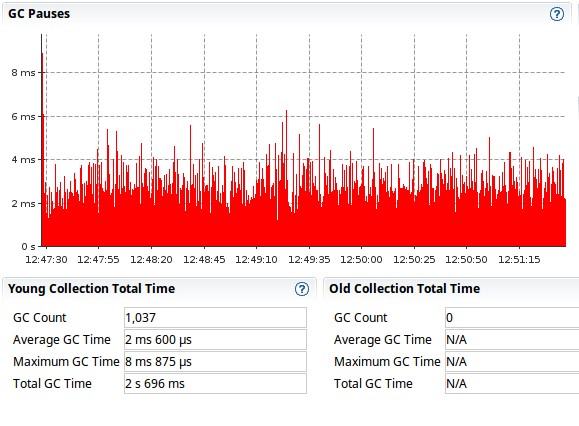
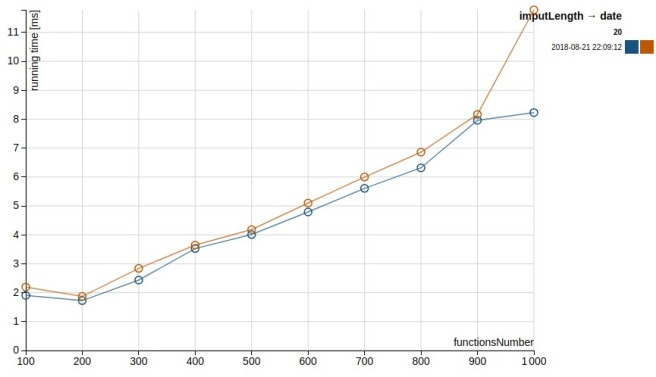
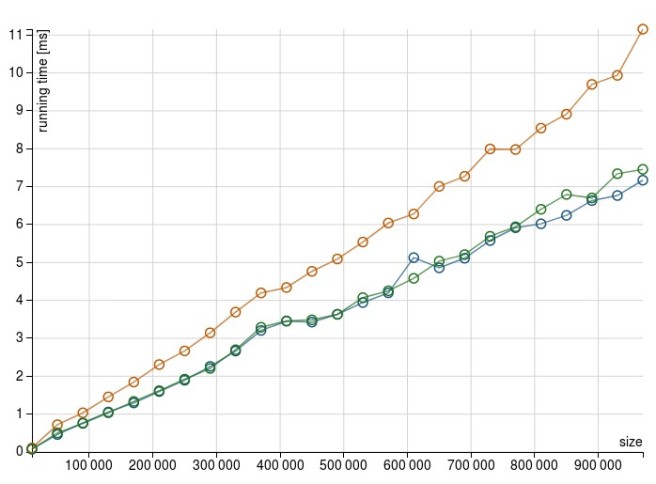
When we run the scala meter tests to get some idea of how the two approaches behave when dealing with 100 new columns, we get the following results1. For foldLeft (addColumnsViaFold method):
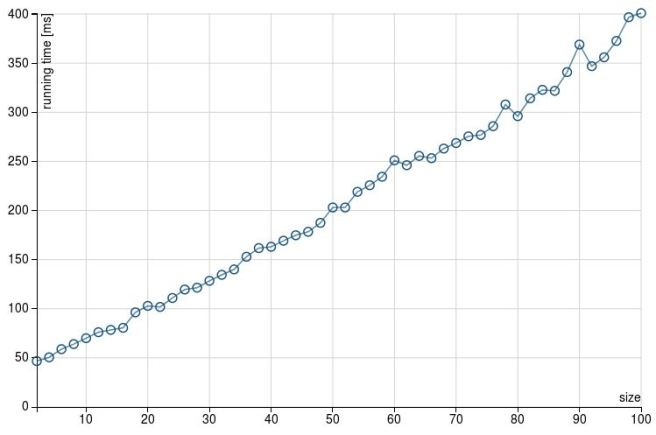
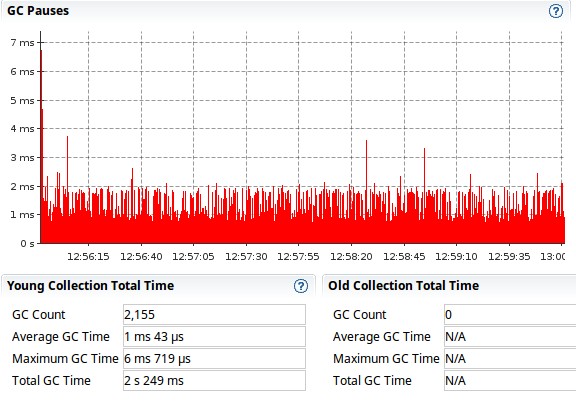
Whereas those one are the results for map (addColumnsViaMap method):

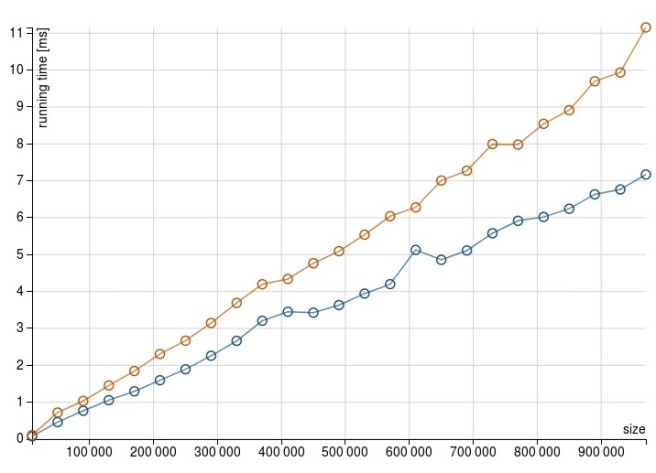
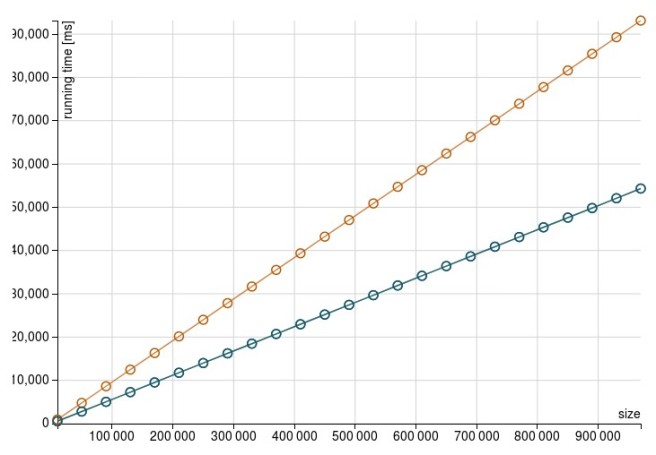
When the number of columns increases, foldLeft is taking considerably more time. If we take the number of columns to 500 the result is similar (and more dramatic)
Once again, for foldLeft :
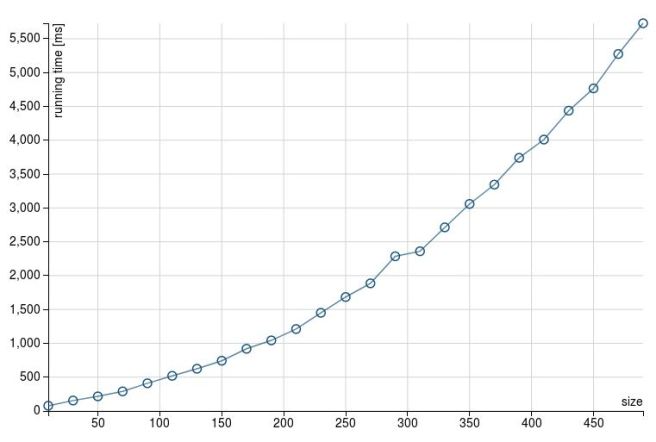
And for map:

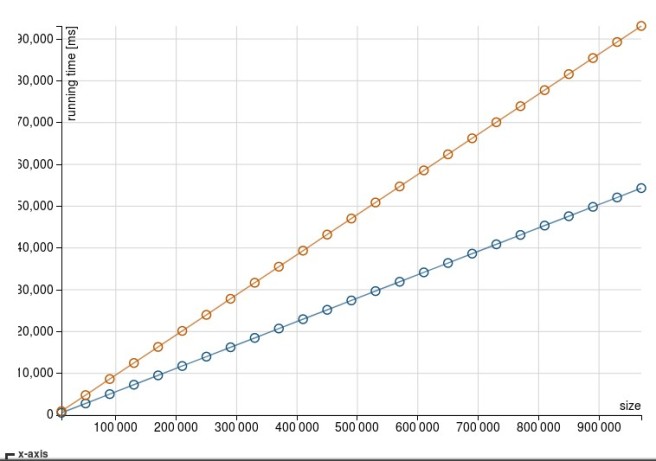
With 1000 columns, foldLeft job aborts:
[error] Error running separate JVM: java.lang.OutOfMemoryError: GC overhead limit exceeded
Probably sign that the heap is running low and the CG can’t free much memory. Still, the map based solution seems to cope much better even with 1000 row:
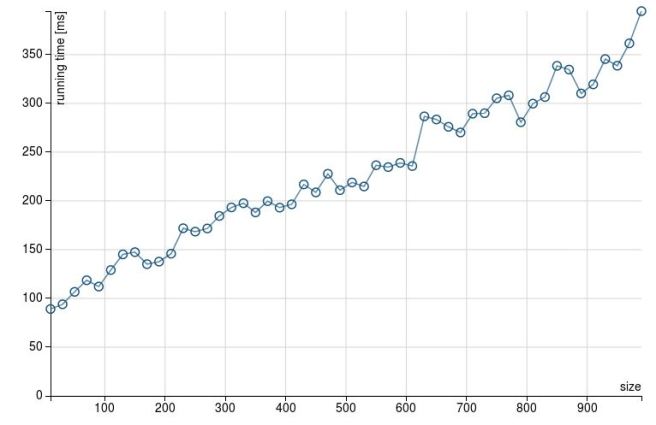
When it comes to the reason behind this different behavior, my guess would be that somehow Catalyst is not able to optimize the foldLeft operation. The below plans (explain(true)) show how the Parsed and Analyzed Logical Plans end up in a sort of nested structure.
== Parsed Logical Plan ==
Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 20 more fields]
+- AnalysisBarrier
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 19 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 18 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 17 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 16 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 15 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 14 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 13 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 12 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 11 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 10 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 9 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 8 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 7 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 6 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 5 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 4 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 3 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 2 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, Contains(incipit#12, toing) AS toing#368]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, Contains(incipit#12, hence) AS hence#342]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, Contains(incipit#12, four) AS four#317]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, Contains(incipit#12, John) AS John#293]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, Contains(incipit#12, pop) AS pop#270]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, Contains(incipit#12, drunk) AS drunk#248]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, Contains(incipit#12, two) AS two#227]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, Contains(incipit#12, when) AS when#207]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, Contains(incipit#12, city) AS city#188]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, Contains(incipit#12, morning) AS morning#170]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, Contains(incipit#12, way) AS way#153]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, Contains(incipit#12, pig) AS pig#137]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, Contains(incipit#12, happy) AS happy#122]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, Contains(incipit#12, was) AS was#108]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, Contains(incipit#12, anna) AS anna#95]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, Contains(incipit#12, in) AS in#83]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, Contains(incipit#12, man) AS man#72]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, Contains(incipit#12, with) AS with#62]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, Contains(incipit#12, alike) AS alike#53]
+- Project [id#9, author#10, title#11, incipit#12, to#38, Contains(incipit#12, get) AS get#45]
+- Project [id#9, author#10, title#11, incipit#12, Contains(incipit#12, to) AS to#38]
+- Project [_1#4 AS id#9, _2#5 AS author#10, _3#6 AS title#11, _4#7 AS incipit#12]
+- LocalRelation [_1#4, _2#5, _3#6, _4#7]
== Analyzed Logical Plan ==
id: int, author: string, title: string, incipit: string, to: boolean, get: boolean, alike: boolean, with: boolean, man: boolean, in: boolean, anna: boolean, was: boolean, happy: boolean, pig: boolean, way: boolean, morning: boolean, city: boolean, when: boolean, two: boolean, drunk: boolean, pop: boolean, John: boolean, four: boolean, hence: boolean, ... 20 more fields
Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 20 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 19 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 18 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 17 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 16 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 15 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 14 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 13 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 12 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 11 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 10 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 9 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 8 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 7 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 6 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 5 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 4 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 3 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, ... 2 more fields]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, hence#342, Contains(incipit#12, toing) AS toing#368]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, four#317, Contains(incipit#12, hence) AS hence#342]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, John#293, Contains(incipit#12, four) AS four#317]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, pop#270, Contains(incipit#12, John) AS John#293]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, drunk#248, Contains(incipit#12, pop) AS pop#270]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, two#227, Contains(incipit#12, drunk) AS drunk#248]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, when#207, Contains(incipit#12, two) AS two#227]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, city#188, Contains(incipit#12, when) AS when#207]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, morning#170, Contains(incipit#12, city) AS city#188]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, way#153, Contains(incipit#12, morning) AS morning#170]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, pig#137, Contains(incipit#12, way) AS way#153]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, happy#122, Contains(incipit#12, pig) AS pig#137]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, was#108, Contains(incipit#12, happy) AS happy#122]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, anna#95, Contains(incipit#12, was) AS was#108]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, in#83, Contains(incipit#12, anna) AS anna#95]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, man#72, Contains(incipit#12, in) AS in#83]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, with#62, Contains(incipit#12, man) AS man#72]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, alike#53, Contains(incipit#12, with) AS with#62]
+- Project [id#9, author#10, title#11, incipit#12, to#38, get#45, Contains(incipit#12, alike) AS alike#53]
+- Project [id#9, author#10, title#11, incipit#12, to#38, Contains(incipit#12, get) AS get#45]
+- Project [id#9, author#10, title#11, incipit#12, Contains(incipit#12, to) AS to#38]
+- Project [_1#4 AS id#9, _2#5 AS author#10, _3#6 AS title#11, _4#7 AS incipit#12]
+- LocalRelation [_1#4, _2#5, _3#6, _4#7]
== Optimized Logical Plan ==
Project [id#9, author#10, title#11, incipit#12, Contains(incipit#12, to) AS to#38, Contains(incipit#12, get) AS get#45, Contains(incipit#12, alike) AS alike#53, Contains(incipit#12, with) AS with#62, Contains(incipit#12, man) AS man#72, Contains(incipit#12, in) AS in#83, Contains(incipit#12, anna) AS anna#95, Contains(incipit#12, was) AS was#108, Contains(incipit#12, happy) AS happy#122, Contains(incipit#12, pig) AS pig#137, Contains(incipit#12, way) AS way#153, Contains(incipit#12, morning) AS morning#170, Contains(incipit#12, city) AS city#188, Contains(incipit#12, when) AS when#207, Contains(incipit#12, two) AS two#227, Contains(incipit#12, drunk) AS drunk#248, Contains(incipit#12, pop) AS pop#270, Contains(incipit#12, John) AS John#293, Contains(incipit#12, four) AS four#317, Contains(incipit#12, hence) AS hence#342, ... 20 more fields]
+- InMemoryRelation [id#9, author#10, title#11, incipit#12], true, 10000, StorageLevel(disk, memory, deserialized, 1 replicas)
+- LocalTableScan [id#9, author#10, title#11, incipit#12]
== Physical Plan ==
*(1) Project [id#9, author#10, title#11, incipit#12, Contains(incipit#12, to) AS to#38, Contains(incipit#12, get) AS get#45, Contains(incipit#12, alike) AS alike#53, Contains(incipit#12, with) AS with#62, Contains(incipit#12, man) AS man#72, Contains(incipit#12, in) AS in#83, Contains(incipit#12, anna) AS anna#95, Contains(incipit#12, was) AS was#108, Contains(incipit#12, happy) AS happy#122, Contains(incipit#12, pig) AS pig#137, Contains(incipit#12, way) AS way#153, Contains(incipit#12, morning) AS morning#170, Contains(incipit#12, city) AS city#188, Contains(incipit#12, when) AS when#207, Contains(incipit#12, two) AS two#227, Contains(incipit#12, drunk) AS drunk#248, Contains(incipit#12, pop) AS pop#270, Contains(incipit#12, John) AS John#293, Contains(incipit#12, four) AS four#317, Contains(incipit#12, hence) AS hence#342, ... 20 more fields]
+- InMemoryTableScan [author#10, id#9, incipit#12, title#11]
+- InMemoryRelation [id#9, author#10, title#11, incipit#12], true, 10000, StorageLevel(disk, memory, deserialized, 1 replicas)
+- LocalTableScan [id#9, author#10, title#11, incipit#12]
Not sure whether that is somehow related to the Catalyst inability to optimize foldLeft but the explained map plan doesn’t show the same nested structure:
== Parsed Logical Plan ==
'SerializeFromObject [validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 0, id), IntegerType) AS id#83, if (assertnotnull(input[0, org.apache.spark.sql.Row, true]).isNullAt) null else staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 1, author), StringType), true, false) AS author#84, if (assertnotnull(input[0, org.apache.spark.sql.Row, true]).isNullAt) null else staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 2, title), StringType), true, false) AS title#85, if (assertnotnull(input[0, org.apache.spark.sql.Row, true]).isNullAt) null else staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 3, incipit), StringType), true, false) AS incipit#86, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 4, to), BooleanType) AS to#87, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 5, get), BooleanType) AS get#88, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 6, alike), BooleanType) AS alike#89, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 7, with), BooleanType) AS with#90, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 8, man), BooleanType) AS man#91, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 9, in), BooleanType) AS in#92, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 10, anna), BooleanType) AS anna#93, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 11, was), BooleanType) AS was#94, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 12, happy), BooleanType) AS happy#95, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 13, pig), BooleanType) AS pig#96, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 14, way), BooleanType) AS way#97, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 15, morning), BooleanType) AS morning#98, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 16, city), BooleanType) AS city#99, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 17, when), BooleanType) AS when#100, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 18, two), BooleanType) AS two#101, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 19, drunk), BooleanType) AS drunk#102, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 20, pop), BooleanType) AS pop#103, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 21, John), BooleanType) AS John#104, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 22, four), BooleanType) AS four#105, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 23, hence), BooleanType) AS hence#106, ... 20 more fields]
+- 'MapElements , interface org.apache.spark.sql.Row, [StructField(id,IntegerType,false), StructField(author,StringType,true), StructField(title,StringType,true), StructField(incipit,StringType,true)], obj#82: org.apache.spark.sql.Row
+- 'DeserializeToObject unresolveddeserializer(createexternalrow(getcolumnbyordinal(0, IntegerType), getcolumnbyordinal(1, StringType).toString, getcolumnbyordinal(2, StringType).toString, getcolumnbyordinal(3, StringType).toString, StructField(id,IntegerType,false), StructField(author,StringType,true), StructField(title,StringType,true), StructField(incipit,StringType,true))), obj#81: org.apache.spark.sql.Row
+- AnalysisBarrier
+- Project [_1#4 AS id#9, _2#5 AS author#10, _3#6 AS title#11, _4#7 AS incipit#12]
+- LocalRelation [_1#4, _2#5, _3#6, _4#7]
== Analyzed Logical Plan ==
id: int, author: string, title: string, incipit: string, to: boolean, get: boolean, alike: boolean, with: boolean, man: boolean, in: boolean, anna: boolean, was: boolean, happy: boolean, pig: boolean, way: boolean, morning: boolean, city: boolean, when: boolean, two: boolean, drunk: boolean, pop: boolean, John: boolean, four: boolean, hence: boolean, ... 20 more fields
SerializeFromObject [validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 0, id), IntegerType) AS id#83, if (assertnotnull(input[0, org.apache.spark.sql.Row, true]).isNullAt) null else staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 1, author), StringType), true, false) AS author#84, if (assertnotnull(input[0, org.apache.spark.sql.Row, true]).isNullAt) null else staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 2, title), StringType), true, false) AS title#85, if (assertnotnull(input[0, org.apache.spark.sql.Row, true]).isNullAt) null else staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 3, incipit), StringType), true, false) AS incipit#86, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 4, to), BooleanType) AS to#87, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 5, get), BooleanType) AS get#88, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 6, alike), BooleanType) AS alike#89, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 7, with), BooleanType) AS with#90, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 8, man), BooleanType) AS man#91, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 9, in), BooleanType) AS in#92, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 10, anna), BooleanType) AS anna#93, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 11, was), BooleanType) AS was#94, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 12, happy), BooleanType) AS happy#95, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 13, pig), BooleanType) AS pig#96, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 14, way), BooleanType) AS way#97, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 15, morning), BooleanType) AS morning#98, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 16, city), BooleanType) AS city#99, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 17, when), BooleanType) AS when#100, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 18, two), BooleanType) AS two#101, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 19, drunk), BooleanType) AS drunk#102, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 20, pop), BooleanType) AS pop#103, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 21, John), BooleanType) AS John#104, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 22, four), BooleanType) AS four#105, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 23, hence), BooleanType) AS hence#106, ... 20 more fields]
+- MapElements , interface org.apache.spark.sql.Row, [StructField(id,IntegerType,false), StructField(author,StringType,true), StructField(title,StringType,true), StructField(incipit,StringType,true)], obj#82: org.apache.spark.sql.Row
+- DeserializeToObject createexternalrow(id#9, author#10.toString, title#11.toString, incipit#12.toString, StructField(id,IntegerType,false), StructField(author,StringType,true), StructField(title,StringType,true), StructField(incipit,StringType,true)), obj#81: org.apache.spark.sql.Row
+- Project [_1#4 AS id#9, _2#5 AS author#10, _3#6 AS title#11, _4#7 AS incipit#12]
+- LocalRelation [_1#4, _2#5, _3#6, _4#7]
== Optimized Logical Plan ==
SerializeFromObject [validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 0, id), IntegerType) AS id#83, if (assertnotnull(input[0, org.apache.spark.sql.Row, true]).isNullAt) null else staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 1, author), StringType), true, false) AS author#84, if (assertnotnull(input[0, org.apache.spark.sql.Row, true]).isNullAt) null else staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 2, title), StringType), true, false) AS title#85, if (assertnotnull(input[0, org.apache.spark.sql.Row, true]).isNullAt) null else staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 3, incipit), StringType), true, false) AS incipit#86, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 4, to), BooleanType) AS to#87, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 5, get), BooleanType) AS get#88, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 6, alike), BooleanType) AS alike#89, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 7, with), BooleanType) AS with#90, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 8, man), BooleanType) AS man#91, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 9, in), BooleanType) AS in#92, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 10, anna), BooleanType) AS anna#93, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 11, was), BooleanType) AS was#94, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 12, happy), BooleanType) AS happy#95, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 13, pig), BooleanType) AS pig#96, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 14, way), BooleanType) AS way#97, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 15, morning), BooleanType) AS morning#98, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 16, city), BooleanType) AS city#99, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 17, when), BooleanType) AS when#100, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 18, two), BooleanType) AS two#101, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 19, drunk), BooleanType) AS drunk#102, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 20, pop), BooleanType) AS pop#103, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 21, John), BooleanType) AS John#104, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 22, four), BooleanType) AS four#105, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 23, hence), BooleanType) AS hence#106, ... 20 more fields]
+- MapElements , interface org.apache.spark.sql.Row, [StructField(id,IntegerType,false), StructField(author,StringType,true), StructField(title,StringType,true), StructField(incipit,StringType,true)], obj#82: org.apache.spark.sql.Row
+- DeserializeToObject createexternalrow(id#9, author#10.toString, title#11.toString, incipit#12.toString, StructField(id,IntegerType,false), StructField(author,StringType,true), StructField(title,StringType,true), StructField(incipit,StringType,true)), obj#81: org.apache.spark.sql.Row
+- InMemoryRelation [id#9, author#10, title#11, incipit#12], true, 10000, StorageLevel(disk, memory, deserialized, 1 replicas)
+- LocalTableScan [id#9, author#10, title#11, incipit#12]
== Physical Plan ==
*(1) SerializeFromObject [validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 0, id), IntegerType) AS id#83, if (assertnotnull(input[0, org.apache.spark.sql.Row, true]).isNullAt) null else staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 1, author), StringType), true, false) AS author#84, if (assertnotnull(input[0, org.apache.spark.sql.Row, true]).isNullAt) null else staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 2, title), StringType), true, false) AS title#85, if (assertnotnull(input[0, org.apache.spark.sql.Row, true]).isNullAt) null else staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 3, incipit), StringType), true, false) AS incipit#86, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 4, to), BooleanType) AS to#87, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 5, get), BooleanType) AS get#88, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 6, alike), BooleanType) AS alike#89, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 7, with), BooleanType) AS with#90, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 8, man), BooleanType) AS man#91, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 9, in), BooleanType) AS in#92, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 10, anna), BooleanType) AS anna#93, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 11, was), BooleanType) AS was#94, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 12, happy), BooleanType) AS happy#95, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 13, pig), BooleanType) AS pig#96, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 14, way), BooleanType) AS way#97, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 15, morning), BooleanType) AS morning#98, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 16, city), BooleanType) AS city#99, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 17, when), BooleanType) AS when#100, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 18, two), BooleanType) AS two#101, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 19, drunk), BooleanType) AS drunk#102, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 20, pop), BooleanType) AS pop#103, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 21, John), BooleanType) AS John#104, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 22, four), BooleanType) AS four#105, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 23, hence), BooleanType) AS hence#106, ... 20 more fields]
+- *(1) MapElements , obj#82: org.apache.spark.sql.Row
+- *(1) DeserializeToObject createexternalrow(id#9, author#10.toString, title#11.toString, incipit#12.toString, StructField(id,IntegerType,false), StructField(author,StringType,true), StructField(title,StringType,true), StructField(incipit,StringType,true)), obj#81: org.apache.spark.sql.Row
+- InMemoryTableScan [id#9, author#10, title#11, incipit#12]
+- InMemoryRelation [id#9, author#10, title#11, incipit#12], true, 10000, StorageLevel(disk, memory, deserialized, 1 replicas)
+- LocalTableScan [id#9, author#10, title#11, incipit#12]
Whatever the root cause is, the conclusion is clear. As per Spark 2.3.0 (and probably previous versions) adding (dynamically) a congruous number of columns to a dataframe should be done via a map operation and not foldLeft for the reasons we’ve seen.
—————————————-
1. [I run the tests on a virtual box with three cores running Spark 2.3.0. Time in milliseconds reflects the underline infrastructure and I would expect different performance on a proper cluster. Nevertheless, that a foldLeft solution performs significantly worse that a map based solution should be an outcome independent of the underline hardware.]↩